有个段子是说现在创业公司招人的如果说自己是「大数据」(Big Data),意思其实是说他们会把日志收集上来,但是从来不看。段子归段子,近些年所谓「微服务」「容器化」等「热门技术」的发展,的确促进了日志收集等技术的发展。而 ELK (Elasticsearch + Logstash + Kibana) 也不再是日志收集与展示系统的铁三角了。本文介绍用 Filebeat 代替 Logstash Shipper,用 Elasticsearch Ingest Node 代替 Logstash Indexer 实现一个更加轻量高效的日志收集与展示系统。
一、Beats
与 Logstash 一样,Beats 也是由 Elastic 公司出品;与 Logstash 不同,Beats 只是 data shipper。Beats 家族共享 libbeat 这个库,每个产品分别实现对不同数据来源的收集。目前官方实现有:
- Filebeat —— 文件
- Metricbeat —— 系统及应用指标
- Packetbeat —— 网络抓包分析,如 SQL, DNS
- Winlogbeat —— Windows 系统日志
- Auditbeat —— 审计数据
- Heartbeat —— ICMP, TCP, HTTP 监控
此外还有数十个社区实现。
Beats 由 Go 实现,因此可以方便地做到单文件无依赖运行,十分适合于大面积部署于不同发行版、不同版本的服务器集群之中。相比 Logstash Shipper 需要在每台机器上安装巨大的 JRuby 依赖,Beats 对小内存机器或容器更加友好。
Filebeat
Filebeat 用于从文件中读取日志,相当于一个高性能的 tail -f,可用于各种 HTTP 服务器的日志收集。以下是一份收集 Nginx 日志的简易配置。完整的配置及模板可在文末的 Ansible Playbook 懒人包中找到。
# 日志源
filebeat.prospectors:
- type: log
paths:
- /var/log/nginx/access.log
- /var/log/nginx/*.access.log
fields:
type: nginx.access
- type: log
paths:
- /var/log/nginx/error.log
fields:
type: nginx.error
# 当检测到运行于 AWS, GCE, DigitalOcean 等平台时,自动添加机器信息
processors:
- add_cloud_metadata:
# 因为我使用了自定义模板,所以这里禁止它加载默认模板
setup.template.enabled: false
# 输出至 Elasticsearch
output.elasticsearch:
hosts: ["http://localhost:9200/"]
# 根据不同的日志类型,使用不同的 Ingest Pipeline
pipelines:
- pipeline: nginx.access
when.equals:
fields.type: nginx.access
- pipeline: nginx.error
when.equals:
fields.type: nginx.error
Cloudfrontbeat
除了 Filebeat,另外值得一提的是社区实现 Cloudfrontbeat。由于我的博客前置了 CloudFront 作为加速和缓存,因此 Nginx 日志中的信息并不完整,而 Cloudfrontbeat 则可以用来解析并上传 CloudFront 边缘节点的日志。
Cloudfrontbeat 的原理是:
- CloudFront 将边缘节点日志记录到 S3 中;
- S3 将
ObjectCreate事件发布到一个 SQS 消息队列中; - Cloudfrontbeat 订阅 SQS 得知新日志产生的事件,从 S3 获取日志文件,解析后灌进 ES。
此外 Cloudfrontbeat 提供了 backfill 模式,可以遍历指定日期范围内已经存在于 S3 内的日志文件,将其信息灌进 SQS,然后再切换成正常的 worker 模式跑起来,就能把旧日志也灌进 ES 了。
Cloudfrontbeat 作者提供了一个 CloudFormation,可以一键把 S3 + SQS 配置好。
二、Elasticsearch Ingest Node
Elasticsearch Ingest Node 是 Elasticsearch 5.0 起新增的功能。在 Ingest Node 出现之前,人们通常会在 ES 前置一个 Logstash Indexer,用于对数据进行预处理。有了 Ingest Node 之后,Logstash Indexer 的大部分功能就可以被它替代了,grok, geoip 等 Logstash 用户所熟悉的处理器,在 Ingest Node 里也有。对于数据量较小的 ES 用户来说,省掉一台 Logstash 的开销自然是令人开心的,对于数据量较大的 ES 用户来说,Ingest Node 和 Master Node, Data Node 一样也是可以分配独立节点并横向扩展的,也不用担心性能瓶颈。
目前 Ingest Node 已支持数十种处理器,其中的 script 处理器具有最大的灵活性。
与 /_template 类似,Ingest API 位于 /_ingest 下面。用户将 pipeline 定义提交之后,在 Beats 中即可指定某 pipeline 为数据预处理器。
对于新安装单节点 ES 集群来说,默认那个节点已经具有 Ingest Node 的 role,无需配置即可直接使用。
文末的 Ansible Playbook 懒人包中包含了我使用的 Ingest Pipeline 配置。在 nginx.access 中,我使用了自定义的 grok pattern:
"grok": {
"field": "message",
"patterns": [
"%{IP:nginx.access.remote_addr} - %{DATA:nginx.access.remote_user} \\[%{HTTPDATE:nginx.access.time_local}\\] \"%{DATA:nginx.access.request}\" %{NUMBER:nginx.access.status} %{NUMBER:nginx.access.bytes_sent} \"%{DATA:nginx.access.http_referrer}\"
TA:nginx.access.http_user_agent}\"( \"%{DATA:nginx.access._kvs}\")?"
],
"ignore_missing": true
}
[...]
"kv": {
"field": "nginx.access._kvs",
"field_split": "\\|",
"value_split": "=",
"target_field": "nginx.access",
"ignore_missing": true,
"ignore_failure": true
}
这个 pattern 兼容标准的 Nginx "combined" 日志格式,也可以支持在此基础上附加任意 K=V 字段,用于记录你关心的、但是不在默认日志格式里其他字段。比如我的 Nginx 日志格式是这样:
log_format main '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent" ' '"' 'host=$host|' 'request_time=$request_time|' 'http_x_forwarded_for=$http_x_forwarded_for|' 'http_cloudfront_viewer_country=$http_cloudfront_viewer_country|' 'upstream_addr=$upstream_addr|' 'upstream_status=$upstream_status|' 'upstream_response_time=$upstream_response_time' '"' ;
前半段是的 "combined" 日志格式,之后你可以附加任意 "k1=v1|k2=v2|k3=v3" 的字段,这些字段都会被 Ingest Pipeline 处理后被 ES 索引。
三、Kibana
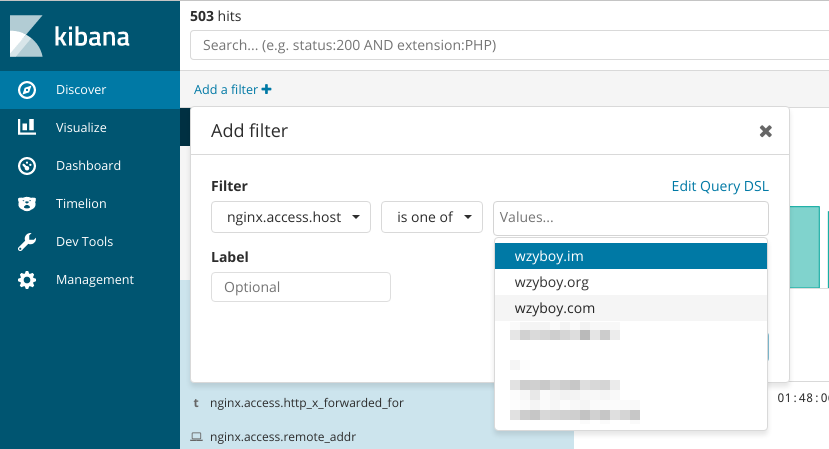
Kibana 是使用 Node.js 构建的 Elasticsearch 展示前端。推荐使用最新版本(6.x),至少也要 5.5 以上,因为 Kibana 5.5 新增了非常好用的 filter UI,可以方便地进行字段过滤,而不用再手写 Lucene 或 ES Query DSL 了:
oauth2_proxy
严格来说这和 Kibana 没什么关系。但是由于 Kibana 自身没有健全的用户认证(默认配置下无任何认证),oauth2_proxy 非常适合前置于 Kibana 作为用户认证。正如它的名字所暗示的,oauth2_proxy 能让任何 HTTP 服务无需改动直接支持 OAuth2 认证。它可以与服务串联使用,也可以在 Nginx auth_request 模块的配合下,进行旁路认证:
location /oauth2/ {
proxy_pass http://127.0.0.1:4180;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_set_header X-Auth-Request-Redirect $request_uri;
}
location /kibana/ {
satisfy any;
auth_request /oauth2/auth;
error_page 401 = /oauth2/sign_in;
allow 127.0.0.1;
deny all;
proxy_pass http://127.0.0.1:5601/;
}
四、Ansible Playbook 懒人包
我写了一个简单的 Ansible Playbook,用于安装以上提到 Filebeat, Elasticsearch, Kibana 和 oauth2_proxy。