如果你想在 Android 上使用五笔输入法,但却不想安装「大厂」那些要一堆权限的输入法、或是觉得它们不好用,那么 Trime 可以满足你的的洁癖与定制需求。
2025-10-12 更新:我早已不再使用本文所述的 Trime 输入法。本文很大一部分是描述通过 Trime 在 Android 上模拟出 Fcitx 的体验。前两年 Fcitx 出 Android 版了,因此直接装 Fcitx5 for Android 即可,无需繁琐的 YAML 配置,开箱即用!本文关于导入 Fcitx 词库的部分依然可供有需要在别的平台(如 Windows 和 macOS)通过 Rime 引擎使用 Fcitx 词库的读者参考。
一、五笔输入法与 Rime
我最早接触五笔是 2001 年左右,浅尝辄止,最终没能熬过最初那段痛苦的学习期。在 2005 年的暑假,我终于一鼓作气翻过了那陡峭的学习曲线,从此之后便一直以五笔作为我在计算机上的唯一输入法。一开始是使用「极点五笔」这个 Windows 平台上的五笔输入法,2010 年左右彻底皈依 GNU/Linux 阵营之后,便以 Fcitx 这个强大的输入平台作为我的五笔输入法,使用至今。
然而我在手机上的文字输入一直很痛苦。最早使用 Nokia 直板机的时候,勉强用 T9 拼音,后来则坚持以全键盘 Android 手机为购机首选——无他,只为能用全键盘畅快地打五笔。可惜历史的车轮毫不留情地辗来,手机越来越薄,拼音输入法越来越好用,前者导致全键盘手机的消亡,后者导致 Android 上五笔输入法的消亡。我也不得不回到了 T9 拼音的怀抱。
前段时间听闻 Gboard 的 iOS 版增加了五笔输入法,甚是欣喜,随后又失望地发现 Android 版并没有这个功能。不甘心的我,第无数次开始调查和试用各种 Android 上输入五笔的实现,这次,终于发现了 Trime。
我在 2012 年曾尝试过 Rime,这是一款定制性极强的跨平台输入法,不过我并没有觉得它比 Fcitx 有什么优势,而它强大的音码(拼音、注音等)定制功能在形码输入法(五笔、仓颉等)面前也没啥大用处,因此我不为所动。
时隔四年,当我看到 Trime 的介绍,说它自己是原本是一款注音仓颉输入法,融合了 Rime 的核心的时候,我仿佛听到了内心深处一个声音对我说:就是它!
二、Rime / Trime 简介
对于未曾听说过 Rime 的读者,本段将简单介绍 Rime / Trime 的基本概念。
首先,Rime 是一个跨平台的输入框架。它的核心(或者说「后端」)是 librime 引擎,不同平台的前端实现共用这个后端。目前在 GitHub RIME 组织中维护的前端实现有三个:
- 用于 Windows 的 Weasel 「小狼毫」;
- 用于 macOS 的 Squirrel 「鼠须管」;
- 用于 Linux 的 ibus-rime 「中州韵」——Rime 本身的中文名字也叫「中州韵输入法引擎」。
此外,还有一些别的前端:
- 和 ibus-rime 一样用于 Linux,但是依托 Fcitx 而不是 IBus 的 fcitx-rime;
- 用于 Android 的 Trime 「同文输入法」;
- 用于 iOS 的 iRime。
本文主要介绍的是 Trime。曾经这个项目是个纯 Java 写的 Android 项目,试图用 Java 重新实现 Rime 的功能(前端 + 后端),但要用另一种语言重写一个项目谈何容易。在 2015 年左右,作者推翻重来,不再重复造轮子,而是借助 JNI 直接使用 librime 核心,Trime 这个项目只负责前端实现。
三、安装与配置 Trime
安装没啥好说的,直接去 Releases 下载安装包,或是从 Play Store 安装皆可。
由于 Rime 的配置主要通过文本文件完成,建议在电脑上编辑这些文件(Rime 要求 UTF-8 w/o BOM,所以你得使用一个得体的编辑器,别拿 Notepad.exe 来糊弄),然后 adb push 进手机。
有必要先说一下 Rime 的配置文件。Rime 的配置文件是 YAML 格式,对人类、对机器都较为友好。Rime 的主要配置文件有这么几个:
- default.yaml —— 各方案共享的全局配置
- default.custom.yaml —— (可选)对 default.yaml 的「补丁」
- XXX.schema.yaml —— XXX 输入方案的配置
- XXX.custom.yaml —— (可选)对 XXX.schema.yaml 的「补丁」
- XXX.dict.yaml —— XXX 输入方案的词库(字典)
其中 XXX 是输入方案的名字,可以有多套输入方案同时存在,比如 wubi86, luna_pinyin, cangjie5 等。以 .custom.yaml 结尾的文件,是对不带 custom 的同名文件的「补丁」。这是一个非常赞的设计,当你对默认的配置文件不满意时,可以通过新建一个补丁文件去修改它,而不是直接去修改原来的文件,这样当原文件的提供者(可能是你的发行版)更新了这个文件的时候,你的改动因为存在于补丁里而得到保留,不会被覆盖掉。当然,如果你的配置文件是自己写的话,你也可以不用补丁文件而直接修改原始文件。有关这些配置文件的详细信息,请参阅官方文档。
除此之外,不同的前端还会有一个自己的配置文件,比如 Trime 就是会有一对额外的 trime.yaml 和 trime.custom.yaml。
和许多软件一样,Rime 的配置也是分「共享/系统」和「用户」的。比如对我的 Arch Linux 里的 fcitx-rime 来说,系统配置位于 /usr/share/rime-data 目录下,而用户配置位于 ~/.confg/fcitx/rime 目录下,后者的优先级高于前者。此外 fcitx-rime 还会在启动时执行一次「部署」,根据原始配置和补丁文件,编译一份合并之后的配置(以及编译出来的二进制词库),放在 ~/.config/fcitx/rime/build 目录里。我想看看自己的补丁并入原文件之后最终的生效配置,就看这里面的文件。
如果你改动了任意配置文件,也需要执行一次「部署」,让 Rime 重新编译新的配置并应用。
对于 Trime 来说,「共享」的配置是位于程序内部的,用户配置则是位于每个用户虚拟出来的 旧版本的 Trime 曾经是原地打补丁的。2019-07-31 在 Play Store 上更新的版本已经拥有的正确的行为,将编译后的配置放在 /sdcard/rime 目录下,只不过 Trime 在「部署」时是原地打补丁,把合并后的配置文件直接写入 /sdcard/rime 里,这个设计令我有点郁闷——补丁中将一个配置变更之后再把这行删掉,也不能回复初始值了,只能把原始文件也 reset 一次再重新部署才行。我对此的处理方法是在把带注释的、排版优美的、原始的 trime.yaml 和 wubi86.schema.yaml 在电脑上也保留一份,每次在电脑上修改 *.custom.yaml 文件之后,连同原始文件一起 adb push 一份到 /sdcard/rime 目录下覆盖同名文件,再执行部署(合并配置),这样能保证每次合并出来的配置不会有脏数据在里面。/sdcard/rime/build 目录里,而不再改动编译前的文件。
安装完 Trime 之后首次启动,你会发现输入方案里只有拼音和仓颉,没有五笔……所以我们要自己来添加一份。从 rime-wubi 项目可以下载到 Rime 的五笔方案,将 wubi86.schema.yaml 和 wubi86.dict.yaml 这两个文件放到 /sdcard/rime 目录里,部署一次,你就拥有了五笔。
然而这默认的五笔并不好用。早已习惯了 Fcitx 中的五笔词库,我用着 Rime 的词库各种别扭。Rime 的第一作者是个生长于中国大陆的繁体字爱好者,默认词库的词频也是按照繁体中文进行统计的,比如编码同样是 vfjf,「書」就排在「那里」和「那时」的前面,这让我很不能接受。此外,之前我在手机上主要使用 Google Pinyin 输入,突然换到 Trime 的键盘布局,十分不习惯。
好在 Rime / Trime 都是高度可定制的,我们先来解决键盘布局的问题。
四、键盘布局向 Google Pinyin 看齐
与 Trime UI 相关的配置都在 trime.yaml 文件。Trime 的作者对该文件有着详尽的文档,默认版本的配置文件中也有详细的注释。要想把 Trime 的键盘改得像 Google Pinyin 一样,最科学的方法便是新建一个键盘布局,然后照着 Google Pinyin 的键位慢慢调。
我已经调好了。图为对比效果:
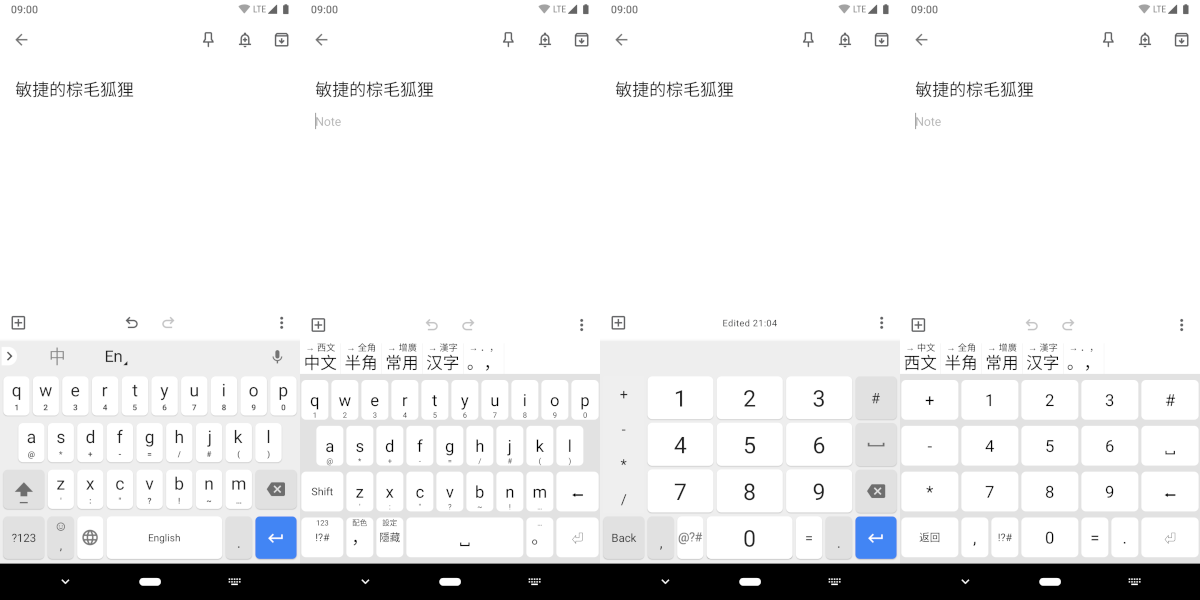
这是打开了按键边框的 Google Pinyin 和 Trime 的对比图(Trime 不支持按键 drop shadow)。还有一些微小的差别,但是键位大致没有错了,按照原来击键习惯去按不会按错了。最重要的是我把 Google Pinyin 那下划输入数字和符号的功能原样搬过来了——这个功能实在是太方便了,换别的输入法也不能没有它!
符号键盘按键实在太多,我没有照排,而是拿 Trime 自带的那个稍做修改,去掉了一排数字键(因为主键盘和九宫格键盘已经能方便地输入数字了),使之能与主键盘做到同高,这里就不再贴图了。
五、词库向 Fcitx 看齐
Fcitx 的五笔词库源自哪里已经不可考(据说是来自「极点五笔」),但它的确挺好用的,而且我用了这么多年也习惯了。正如上文所说,Rime 的五笔方案是按繁体中文的词频排序的,让我难受。还记得上文的的 wubi86.schema.yaml 和 wubi86.dict.yaml 么?后者可以删除了,我们把 Fcitx 的五笔词库移植到 Trime 里来!
Rime 的词库也是个 YAML 文件,但只有前面一部分(--- 与 ... 之间)是 YAML 文档的本体,之后是个 TSV 列表。比如我新建的 fcitx_wbx.dict.yaml 的 YAML 部分长这样(我添加了注释):
----
name: fcitx_wbx
version: "1"
import_tables: # 导入其他的词库,可复用设计
- zz
- weight0
sort: original # 设定是按文件里的顺序决定重码候选词的顺序,还是按照权重(by_weight)
columns: # TSV 的表头,默认是 text, code, weight。额外的 stem 仅用于 25 个一级简码,用来处理它们单打和组词时编码不一致的问题
- text
- code
- weight
- stem
encoder: # 组词规则!有了单字的编码之后,词语的编码是可以自动生成的,无需手动编码
exclude_patterns:
- '^z.*$'
rules: # 熟悉五笔的肯定能看出,这是「一二三末」的拆词口诀,用公式表达的样子
- length_equal: 2
formula: "AaAbBaBb"
- length_equal: 3
formula: "AaBaCaCb"
- length_in_range: [4, 10]
formula: "AaBaCaZa"
...
Fcitx 的网站上有直接的 .txt 版本的词库下载的,但如果你像我一样也是一个 Fcitx 用户的话,本地可能会积累了一些用户词库,因此我们可以用 Fcitx 自带的 mb2txt 工具将本地的二进制词库转成纯文本,再排成 Rime 的词库格式,附在上述 YAML 文档的末尾:
mb2txt ~/.config/fcitx/table/wbx.mb | sed '1,/^\[Data\]/d' | awk '{print $2 "\t" $1}' >> fcitx_wbx.dict.yaml
除了 Fcitx 的词库,我还额外做了两个小词库,一个是「极点五笔」那套用 zz 开头快速输入一些特殊符号的词库,另一个是从 Rime 自带的 wubi86.dict.yaml 词库中过滤出来的、Fcitx 词库中没有的生僻字(约五万个)。这是三个成品词库:
- fcitx_wbx.dict.yaml —— Fcitx 自带的五笔词库
- zz.dict.yaml —— 极点五笔 zz 快速输入词库
- weight0.dict.yaml —— 五万生僻字词库
后两个词库在第一个词库的 YAML 文档中用 import_tables 指令导入,如果你不喜欢 Fcitx 的词库而选择了别的输入法的词库,也可以这样导入。
值得注意的是,Rime 默认是过滤掉生僻字候选的(见上文截图中「常用/增广」开关),所以不用担心加入了五万生僻字词库会导致一堆令人难受的重码,更何况生僻字都设置了权重为 0,即使和别的候选词一起出现,也一定是排在最后面的。
设计完自己的新词库之后,便可以新建一个 wubi86.custom.yaml 文件,对 wubi86.schema.yaml 这个输入方案打补丁(当然你想直接修改原文件也可以):
patch:
translator/dictionary: fcitx_wbx
把相关文件全部放到 /sdcard/rime 目录下,重新部署,就能在 Trime 里用上 Fcitx 的词库了。
六、更多设置
自动上屏
大部分五笔输入法都是应该自动上屏的(因为大部分情况下只有一个候选词),但 Rime 默认开启了「语句流」模式,可以用类似拼音整句输入的方式打五笔。这个功能可以这样关闭:
patch:
translator/enable_sentence: false
speller/max_code_length: 4
speller/auto_select: true
speller/auto_select_unique_candidate: true
拼音反查
默认是用 z 进行拼音反查,和 zz 快速输入混在一起比较不爽。我还是习惯用 ` 进行反查:
patch:
reverse_lookup/prefix: "`"
recognizer/patterns/reverse_lookup: "^`[a-z]*'?$"
补充:拼音反查功能依赖一套拼音输入法,默认为 pinyin_simp,可从 rime-pinyin-simp 下载 pinyin_simp.schema.yaml 和 pinyin_simp.dict.yaml 文件放入 /sdcard/rime 目录下。
简入繁出
Rime 支持使用 OpenCC 进行简繁转换,用这个补丁可以打开:
patch:
engine/filters:
- simplifier
- uniquifier
simplifier:
opencc_config: s2t.json
option_name: zh_trad
switches/@before last:
name: zh_trad
states: ["汉字", "漢字"]
这样会在 Trime 的状态栏里多一个简繁选择开关(见上面的截图),打开或关闭简繁转换。在上面的设置中 opencc_config 决定了使用哪套转换配置,这个 s2t.json 只对字进行转换,如果换成 s2twp.json 的话则会按照台湾用词习惯对词进行转换,比如输入「软件」会输出「軟體」。小心不要闹出「海記憶體知己」这样的笑话就好。更多可用的转换方案可查看 /sdcard/rime/opencc 目录。
进一步扩展词库
Rime 的词库管理如此灵活、方便,不好好利用有点浪费。在折腾完上面的东西之后,我就想着怎么给 Trime 进一步扩展一下词库了(上文已经扩展了五万平时不会出现在候选里的生僻字)。王永民先生其实并不推荐大词库,因为大词库势必会增加重码率(想想 qtqt 和 khkh 有多少重码)。Fcitx 的词库不算大(3.2 万单字,6.7 万词语),但是我考虑再三,在手机上用 Trime 打五笔的话,还是大词库比较好,原因有三:
- 手机上打字,通常是比较口语化的内容,大词库收录的口语短语较多;
- 词库大一点,分词长一点,能减少在手机上击键的次数;
- 手机屏幕小,选词不如电脑上那么影响效率。
此外,我打算增加的词库是会排在主词库的后面的,按照 Rime 的词库编译算法,这些候选词的优先级会比来自主词库的词低。
我最终选择的是「点儿词库」。这其实是个 09 五笔用的词库,其字根和编码方式和 86 版、98 版、新世纪版不一样。好在 Rime 可以根据单字的编码,自动为词组计算其编码,所以只要把「点儿词库」中的词头过滤出来就行,编码可以舍弃。最终我制作的加入了「点儿词库」所有二字及以上词语的扩展词库在这里:fcitx_wbx.092m.dict.yaml。在去掉所有单字、去掉 Fcitx 词库中已有的词语之后,「点儿词库」依然可以有近 5 万的词语条目。至此,我的 Trime 的五笔词库已扩展至 8.1 万单字、11.6 万词语。
要使用该词库,设置 translator/dictionary: fcitx_wbx.092m 即可。如果重新部署之后能用 tcgg 打出「我能吞下玻璃」即说明应用成功了(这是我加的测试用例)。
既然已经有了大词库,那用户字典和词频调整也可以关闭了:
patch:
translator/enable_user_dict: false
生僻字专用字体
针对词库里的生僻字,Trime 还有个贴心的小设计:使用专门的字体来显示 CJK Ext-B 及之后的汉字。目前已知的唯一一款(如果你知道有别的,欢迎在下面留言)做到 CJK Ext-B 至 CJK Ext-F 六万多个汉字全部收录的字体是花园明朝(花園明朝)。将 HanaMinB.ttf 复制到 /sdcard/rime/fonts 目录中,然后对 trime.yaml 打补丁:
patch:
"style/hanb_font": HanaMinB.ttf
即可在 Trime 中显示出所有能打出来的汉字,即使这个汉字在其他系统里显示不了……
本文地址: https://wzyboy.im/post/1251.html