我的 MicroServer Gen8 已经服役四年有余了,差不多也该退休了。于是最近买了一台 MicroServer Gen10 Plus。
一、HPE MicroServer 系列简介
HPE MicroServer 是 HPE ProLiant 面向家庭与小型办公室的入门级服务器产品。其特点是体积小、噪音低、扩展性强、外观美观。这个系列至今有四代产品:
- MicroServer (2010) —— 默默无闻的一代产品,因使用 AMD 平台而饱受诟病;
- MicroServer Gen8 (2014) —— 在 /r/HomeLab 社区非常流行的一代产品。Intel 平台,可自行升级至 Xeon E3 CPU,性价比很高;
- MicroServer Gen10 (2017) —— AMD 平台、不可更换 CPU、去掉了 iLO。业界评论认为 HPE 是在开倒车(1、2);
- MicroServer Gen10 Plus (2020) —— 回归 Intel 平台,支持 iLO(虽然要加钱)。明明是巨大的升级,却只是在前代名字上加了个「Plus」。
本文介绍的是 2020 年的 MicroServer Gen10 Plus。关于 2014 年的 MicroServer Gen8,可阅读拙作《HP ProLiant MicroServer Gen8 上手玩》和《MicroServer Gen8 改造小记》。
二、购买
Gen8 和 Gen10 有五个 SATA 接口(四个 3.5 吋硬盘,一个光驱),常见配置法是把四块硬盘插满,然后拿光驱的 SATA 接一个 2.5 吋 SSD,用来装系统。Gen10 Plus 去掉了光驱,只有四个 SATA 接口了,因此想要最大化利用四个 3.5 吋硬盘位的话,就要把想办法把系统装在别的地方。主板上的 USB 接口依然被保留了,但是与前面板、后面板的 USB 3.x 接口不同,这个接口是 USB 2.x 的!于是我决定通过 M.2–PCIe 转接卡,用 M.2 SSD 启动。Gen10 Plus 只有一个 PCIe 插槽,所以这样做之后就不能再插其他 PCIe 设备了,比如显卡,或是 10GbE 网卡。不过 Gen10 Plus 是支持 PCIe bifurcation 的,有兴趣的读者可以调研一下 M.2 SSD 与 10GbE 共存的可能性。
更新:根据读者反馈,的确是有 M.2 SSD 与 10GbE 共存的 PCIe 卡的,比如 QNAP QM2-2P10G1TA / QM2-2S10G1TA,均可连接两条 M.2 SSD 并提供 10GbE 网口。
更新:根据读者 Ben 的评论,上述 QNAP 因为散热片过大无法塞进 Gen10 Plus 机箱里。
四年前买 Gen8 的时候我只买了一块 WD Red 2 TB,存满之后又先后加了两块 WD Red 4 TB。时代不同了,4 TB 的硬盘已经过气了,现在最大的硬盘容量已经 16 TB 了(但是很贵)。根据 Backblaze 的报告,WD Red 的可靠性也不怎么样。最终我选择了 price per GB 较低的 Seagate Ironwolf 8 TB。这次想直接使用 mdadm 组 RAID 5(而不是使用 mergerfs 和 SnapRAID),所以干脆一次买了四块。
以下是我的购物清单:
| 项目 | 价格(税前) |
|---|---|
| HPE MicroServer Gen10 Plus (SKU P16006-001; Intel Xeon 2220 CPU; 16 GB RAM) | 852.74 CAD |
| HPE MicroServer Gen10 Plus iLO Enablement Kit (SKU P13788-B21) | 105.46 CAD |
| Samsung 970 EVO Plus 500 GB NVMe M.2 SSD | 159.99 CAD |
| EZDIY-FAB M.2 to PCIe Adapter | 15.59 CAD |
| Seagate Ironwolf 8 TB (ST8000VN004) * 4 | 299.00 CAD * 4 = 1196.00 CAD |
| CyberPower ST425 UPS | 62.54 CAD |
合计税前价格为 2392.32 CAD,按当前汇率(1 CAD ≈ 5.21 CNY)折合约 12470 CNY。
三、开箱












四、PCIe Passthrough(直通)
我在 Gen8 上采用的虚拟化方案是基于 QEMU / KVM 的 Proxmox VE,在 Gen10 Plus 上也打算继续这么用。为了让虚拟机能使用整块硬盘,我之前用了 block passthrough 的方式,把 /dev/disk/ 下的块设备传递给 VM 供其使用。对于 Gen10 Plus 来说,我可以更进一步:把整个 SATA 控制器传递给 VM 使用。Gen8 的启动盘是接在 SATA 控制器上的,所以不能把 SATA 控制器直通,但是 Gen10 Plus 的启动盘是接在 PCIe 转接卡上的 NVMe SSD,所以完全可以把 SATA 控制器的控制权从宿主机移交到虚拟机。
做直通前,在 PVE 里可以看到 sda + sdb + sdc + sdd 四块 SATA HDD,以及 PVE 所在的 NVMe SSD:
root@tenplus:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 7.3T 0 disk
sdb 8:16 0 7.3T 0 disk
sdc 8:32 0 7.3T 0 disk
sdd 8:48 0 7.3T 0 disk
nvme0n1 259:0 0 465.8G 0 disk
├─nvme0n1p1 259:1 0 1007K 0 part
├─nvme0n1p2 259:2 0 512M 0 part /boot/efi
└─nvme0n1p3 259:3 0 465.3G 0 part
├─pve-swap 253:0 0 8G 0 lvm [SWAP]
├─pve-root 253:1 0 96G 0 lvm /
├─pve-data_tmeta 253:2 0 3.5G 0 lvm
│ └─pve-data 253:4 0 338.4G 0 lvm
└─pve-data_tdata 253:3 0 338.4G 0 lvm
└─pve-data 253:4 0 338.4G 0 lvm
通过 lspci 可以看到 SATA 控制器的 ID:
00:17.0 SATA controller [0106]: Intel Corporation Cannon Lake PCH SATA AHCI Controller [8086:a352] (rev 10)
Subsystem: Hewlett Packard Enterprise Cannon Lake PCH SATA AHCI Controller [1590:028d]
Kernel driver in use: ahci
Kernel modules: ahci编辑 /etc/default/grub 文件,在内核参数中打开 Intel IOMMU 功能,并用 vfio-pci 接管 SATA 控制器:
GRUB_CMDLINE_LINUX_DEFAULT="quiet intel_iommu=on vfio-pci.ids=8086:a352"执行 update-grub 或 grub-mkconfig -o /boot/grub/grub.cfg 更新 GRUB 配置,然后重启。再执行 lspci,就能看到 SATA 控制器的驱动由 ahci 变成了 vfio-pci:
00:17.0 SATA controller [0106]: Intel Corporation Cannon Lake PCH SATA AHCI Controller [8086:a352] (rev 10)
Subsystem: Hewlett Packard Enterprise Cannon Lake PCH SATA AHCI Controller [1590:028d]
Kernel driver in use: vfio-pci
Kernel modules: ahci此时再执行 lsblk,可以看到四块 SATA HDD 消失了:
root@tenplus:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme0n1 259:0 0 465.8G 0 disk
├─nvme0n1p1 259:1 0 1007K 0 part
├─nvme0n1p2 259:2 0 512M 0 part /boot/efi
└─nvme0n1p3 259:3 0 465.3G 0 part
├─pve-swap 253:0 0 8G 0 lvm [SWAP]
├─pve-root 253:1 0 96G 0 lvm /
├─pve-data_tmeta 253:2 0 3.5G 0 lvm
│ └─pve-data 253:4 0 338.4G 0 lvm
└─pve-data_tdata 253:3 0 338.4G 0 lvm
└─pve-data 253:4 0 338.4G 0 lvm
新建一个 VM,配置其使用宿主机的 00:17 PCI 设备,即上文的 SATA 控制器(对应的配置项是 hostpci0: 00:17,pcie=1)。在 VM 里执行 lspci,可以看到直通已经成功(由于宿主机 Debian 与虚拟机 Arch 的硬件数据库不同,所以名字稍有差异,但 ID 是一样的):
01:00.0 SATA controller [0106]: Intel Corporation Cannon Lake PCH SATA AHCI Controller [8086:a352] (rev 10)
Subsystem: Hewlett Packard Enterprise Device [1590:028d]
Kernel driver in use: ahci在虚拟机里执行 lsblk 可以看到四块 SATA HDD 跑里面来了:
[wzyboy@eureka ~]$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 7.3T 0 disk
sdb 8:16 0 7.3T 0 disk
sdc 8:32 0 7.3T 0 disk
sdd 8:48 0 7.3T 0 disk
sde 8:64 0 32G 0 disk
└─sde1 8:65 0 32G 0 part /
sr0 11:0 1 662M 0 rom
此时可以在虚拟机里使用底层的 SATA 命令对硬盘进行操作了(如 smartctl -x /dev/sda),配置 smartd 等监控自然也不在话下。
2023-07-04 更新:我在升级 PVE 版本之后发现透传失效了。虽然在 /proc/cmdline 里能看到那些内核参数依然在,但是 lspci 看到 SATA 控制器是由 ahci 管理的,并且在宿主机上 lsblk 能看到 SATA 硬盘。经过排查后,我发现,在新版内核里,vfio-pci 模块的加载顺序比 ahci 模块晚,导致 vfio-pci 加载的时候,SATA 控制器已经被 ahci 模块接管了,导致透传失败。解决方法是手动调整模块加载顺序。在 /etc/modprobe.d/ 里新建一个文件比如 vfio.conf,写入一行:
softdep ahci pre: vfio-pci
根据 modprobe.d(5) 的说明,softdep 可以指定模块之间的依赖关系。这样 vfio-pci 就会在 ahci 模块之前加载,优先接管你在内核参数里指定的 SATA 控制器。
改完文件之后运行 update-initramfs,重启后可观察到 SATA 透传恢复了正常。
五、建立 RAID 与 LVM
由于 Gen8 的硬盘是分批购置的且大小不一,我采用的是 mergerfs + SnapRAID 这样的合并空间及冗余方案。这次 Gen10 Plus 一下子就把四块硬盘买齐了,我打算直接用 mdadm 建 RAID 5 了。
互联网上(尤其是 /r/DataHoarder 社区)广为流传着 RAID 5 不安全的传言。但其实对于四块盘的家用阵列来说,RAID 5 完全没问题。用 smartd 做好监控,早发现、早治疗就行了。
由于是新盘,并不需要 mdadm --misc --zero-superblock 擦除旧阵列痕迹,分好区(gdisk 分区代码 FD00)之后直接组建新阵列就行:
$ sudo mdadm --create /dev/md/r5 --level=5 --raid-devices=4 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
组建几乎是瞬间完成的,但是 mdadm 会对阵列进行一次 resync 操作,以确保数据是一致的(新盘的话,肯定是一致的)。根据磁盘大小,这个过程可能要几个小时才能完成。默认每块盘的限速是 200 MiB/s,所以 8 TB 的磁盘大概需要 10.6 小时完成:
$ cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md127 : active raid5 sdd1[4] sdc1[2] sdb1[1] sda1[0]
23441679360 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [UUU_]
[>....................] recovery = 0.3% (26806356/7813893120) finish=629.2min speed=206240K/sec
bitmap: 0/59 pages [0KB], 65536KB chunk
unused devices: <none>
$ sudo mdadm --detail /dev/md/r5
[...]
Number Major Minor RaidDevice State
0 8 1 0 active sync /dev/sda1
1 8 17 1 active sync /dev/sdb1
2 8 33 2 active sync /dev/sdc1
4 8 49 3 spare rebuilding /dev/sdd1
但这时候阵列已经可用了。RAID 5 会使用相当于一块盘的容量来存储校验值,因此四块 8 TB 的硬盘将得到 24 TB (21.9 TiB) 的阵列。如此大的合并容量,再加一层 LVM 更方便分区规划:
$ sudo pvcreate /dev/md/r5
$ sudo vgcreate vg /dev/md/r5
$ sudo lvcreate -n public -L 20T vg
$ sudo lvcreate -n borg -L 1T vg
$ sudo lvcreate -n urbackup -L 500M vg
其中 borg 卷是给 BorgBackup 使用的;而 urbackup 卷是打算尝试 UrBackup 用的,其推荐的文件系统是(名声不太好的)btrfs,因此我单独分了一个逻辑卷给它。
最后得到了这样的存储结构:
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 7.3T 0 disk
└─sda1 8:1 0 7.3T 0 part
└─md127 9:127 0 21.9T 0 raid5
├─vg-public 253:0 0 20T 0 lvm /media/public
├─vg-borg 253:1 0 1T 0 lvm /media/borg
└─vg-urbackup 253:2 0 500G 0 lvm /media/urbackup
sdb 8:16 0 7.3T 0 disk
└─sdb1 8:17 0 7.3T 0 part
└─md127 9:127 0 21.9T 0 raid5
├─vg-public 253:0 0 20T 0 lvm /media/public
├─vg-borg 253:1 0 1T 0 lvm /media/borg
└─vg-urbackup 253:2 0 500G 0 lvm /media/urbackup
sdc 8:32 0 7.3T 0 disk
└─sdc1 8:33 0 7.3T 0 part
└─md127 9:127 0 21.9T 0 raid5
├─vg-public 253:0 0 20T 0 lvm /media/public
├─vg-borg 253:1 0 1T 0 lvm /media/borg
└─vg-urbackup 253:2 0 500G 0 lvm /media/urbackup
sdd 8:48 0 7.3T 0 disk
└─sdd1 8:49 0 7.3T 0 part
└─md127 9:127 0 21.9T 0 raid5
├─vg-public 253:0 0 20T 0 lvm /media/public
├─vg-borg 253:1 0 1T 0 lvm /media/borg
└─vg-urbackup 253:2 0 500G 0 lvm /media/urbackup
sde 8:64 0 32G 0 disk
└─sde1 8:65 0 32G 0 part /
sr0 11:0 1 1024M 0 rom
RAID 5 理论上是会提升一些写入性能的。测个速:
$ dd if=/dev/zero of=test bs=1M count=2048 conv=fdatasync,notrunc
2048+0 records in
2048+0 records out
2147483648 bytes (2.1 GB, 2.0 GiB) copied, 4.64218 s, 463 MB/s
还行。啊,24 TB 的阵列,真香。
六、数据迁移
Gen8 里有 7 TiB 左右的数据需要迁移到 Gen10 Plus 上。目前 Gen8 在中国,而 Gen10 Plus 和我在加拿大,两台服务器之间物理相隔了一个太平洋,而 COVID-19 期间 FedEx 的带宽又不太稳定,我估算了一下时间,决定通过互联网传输。
这么大的数据量,其实已经不太适合用 rsync 了,且考虑到跨洋传输的不稳定性、中国电信宽带地址的动态变化等问题,我需要一个鲁棒性更强的传输方案。在考察了 Resilio Sync(原 BT Sync)和 Syncthing 之后,我最终选择了后者。
Syncthing 的发送方需要先把所有的数据都 hash 一遍,以 Gen8 的 Celeron G1610T CPU,hash 的速率只有 100+ MiB/s,这些数据用了两天才 hash 完。我在等 Gen10 Plus 寄到的过程中就开始 hash 了,所以倒也没浪费什么时间。一旦 hash 完之后,传输倒是挺顺的。这是传输开始一段时间后的截图:
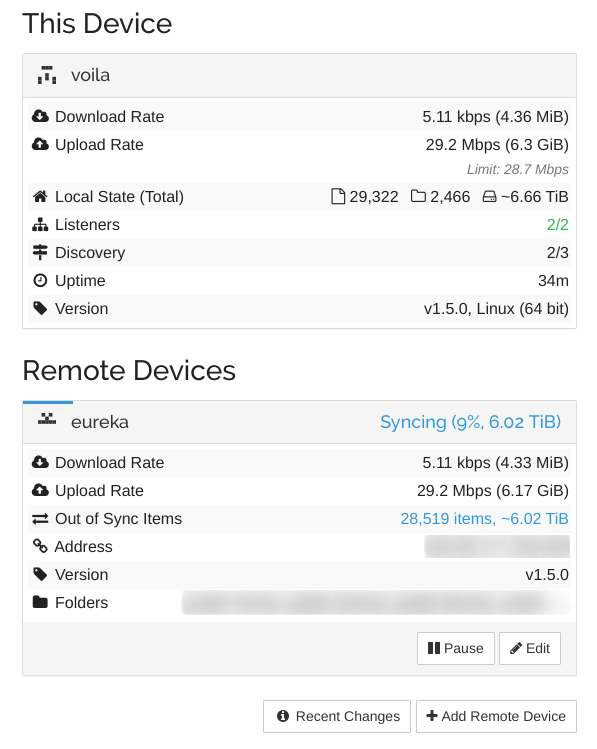
可以看到,一共 6.66 TiB 的数据,按照我设置的 3500 KiB/s (28.7 Mbps) 的限速,也就传个 23 天左右就传完了吧。
截至今天,这些数据已经传输了 21%,状态良好。值得一提的是,刚开始使用默认随机高端口(UPnP)的时候,每隔几小时就会断一次,虽然一分钟内都会重连,但总觉得不爽,怀疑是 GFW 在作祟。我在 EdgeRouter 上加了条 DNAT 规则,使用 443/tcp 传输之后(Syncthing 的流量是正宗的 TLS 流量),跑了两天都没有任何一个连接超时。
本文地址: https://wzyboy.im/post/1387.html
读者来信
2021-06-26 读者 Yongming Wu <e...@me.com> 来信表示,他即使将 vfio-pci.ids 加入启动参数(注:可通过 /proc/cmdline 文件观察当前的启动参数),SATA 控制器依然由 ahci 驱动管理(注:可通过 lspci 观察)。最后他通过在 /etc/modprobe.d/pve-blacklist.conf 文件中屏蔽 ahci 驱动成功实现了 SATA 直通。
2023-07-04 更新:我也遇到了读者 Yongming Wu 遇到的问题。请参考上文中用 softdep 调整模块加载顺序的方法而不是屏蔽整个 ahci 驱动的方法解决问题。该解决方案也已反馈给读者。